Minh Nguyệt - Cô gái xinh xắn dễ thương và hành trình chinh phục chứng chỉ ISTQB
we are vareal🤖
テクノロジーコーナー
2026.04.08
⏱ 記事の総閲覧時間:17分
AI対応アプリケーションのアーキテクチャ: Full Stack JSで考えるフロントエンドからオーケストレーション層まで
V
Software Development Department
Vareal Vietnam
チームが製品にAIを組み込み始めるとき、よくある誤解があります。
多くの人は、
フロントエンドを作る
モデルAPIを呼ぶ
結果を画面に出す
これで「AI対応プロダクト」ができたと考えがちです。
デモとしてはそれで十分かもしれません。
しかし、実際のユーザー、実際のデータ、実際の期待値、実際の障害がある本番環境では、話はそこまで単純ではありません。
AIは単なる新機能ではありません。多くの場合、プロダクトの振る舞いとシステムアーキテクチャの間に、新しい技術レイヤーを持ち込みます。このレイヤーを最初から明確に捉えていないと、よくある状態に陥ります。デモはスムーズなのに、本番では遅い、デバッグしにくい、コストが読みにくい、ユースケースが増えるほど構造が崩れていく、という状態です。
Full Stack JSで製品を作るチームにとって、もはや問いは
「モデルを呼べるか」
ではありません。
本当の問いはこうです。
AIを単なるAPI呼び出しの付け足しではなく、製品の運用可能な一部にするために、アーキテクチャをどう組むべきか。
まず一つの現実から: AIはUIの中に直接置くべきではない
初期段階では、多くのチームが次のような自然な流れで実装します。
フロントエンドがバックエンドを呼ぶ
バックエンドがモデルを呼ぶ
モデルが結果を返す
フロントエンドが表示する
これはプロトタイプには十分です。ですが、製品が次のような要件を持ち始めると、この形はすぐ限界を見せます。
複数種類のリクエスト
複数のデータソース
複数段階の処理
retry、logging、fallback
tokenやcostの管理
複数モデルや外部ツールの組み合わせ
理由は単純です。AIはもはや「入力したら出力が返る関数」ではなくなります。むしろ状態を持つワークフローに近づいていきます。分岐があり、例外があり、プロダクトが制御すべきポイントが増えていく。
だからこそ、アーキテクチャには明確な中間層が必要になります。
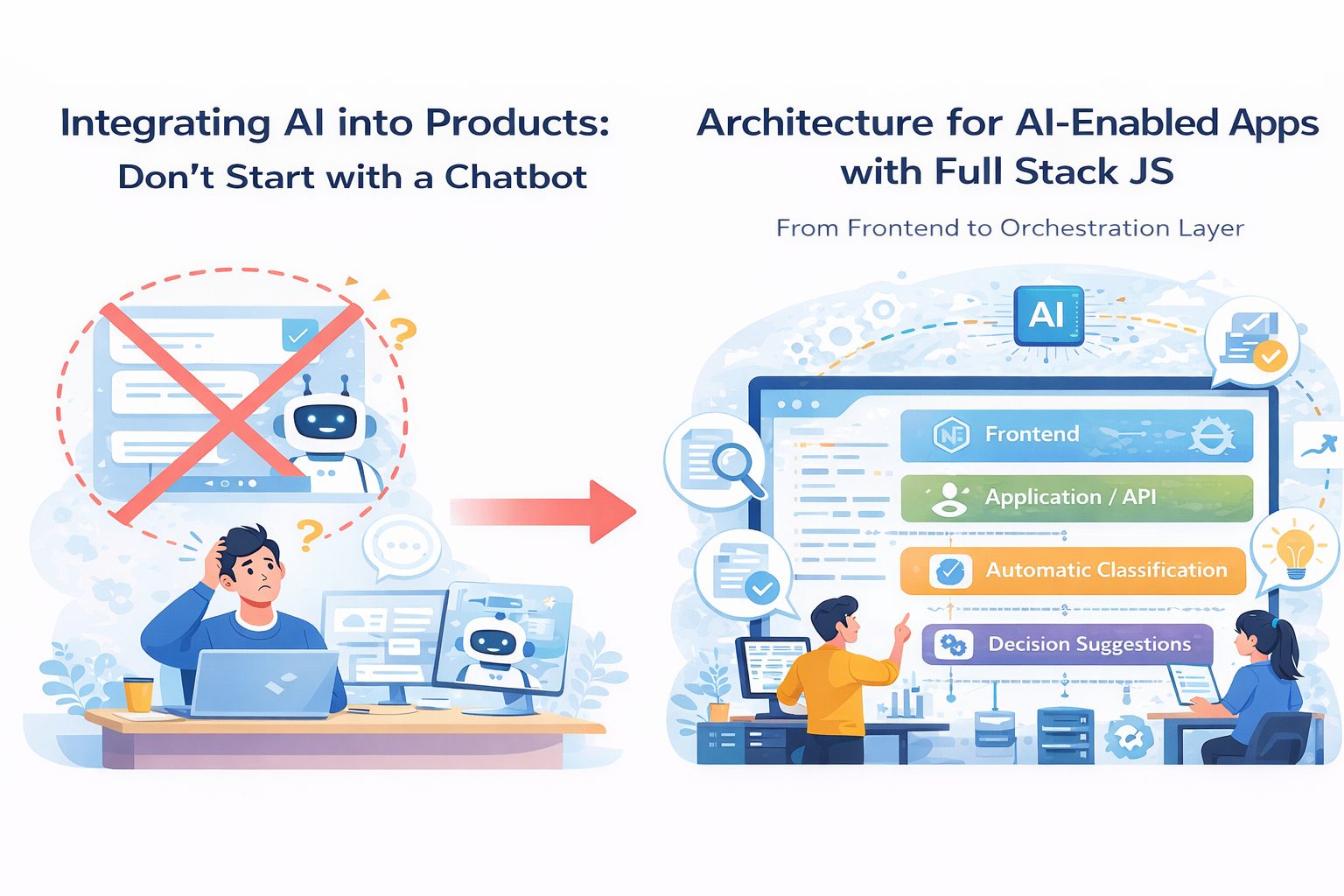
4つのレイヤーで捉える
私はAI対応アプリケーションを、だいたい4つのレイヤーで捉えることが多いです。
1. Frontend / Experience Layer
ユーザーが触る層です。
チャットUI
入力フォーム
コンテンツ生成画面
提案ダッシュボード
AI出力のレビュー画面
Full Stack JSなら通常は、
React
Next.js
TypeScript
などです。
重要なのはフレームワークではなく、フロントエンドがAIロジックを抱えすぎないことです。UIは次に集中すべきです。
入力を受け取る
状態を見せる
処理中を伝える
出力を表示する
レビュー、フィードバック、再実行を支える
つまり、フロントエンドはAI体験を見せる場所ではあっても、AIをオーケストレーションする場所ではないということです。
2. Application / API Layer
プロダクトに最も近いバックエンド層です。
認証
リクエスト検証
セッションやユーザー文脈
API契約
基本的なビジネスルール
機能単位のルーティング
Full Stack JSでは通常、
Next.js server routes
Node.js API layer
Express / NestJS / Fastify
などになります。
多くのチームはここから直接モデルを呼びます。初期段階ではそれでも動きます。ただし、AIユースケースが増えると、この層はすぐ肥大化します。ビジネスAPIとAIワークフロー管理を同時に背負うからです。
だから第三の層が重要になります。
3. Orchestration Layer
多くのチームが最初に見落としやすいのに、AI対応製品の成否をかなり左右する層です。
この層では次のようなことを扱います。
どのモデルを使うか
promptやcontextをどう組み立てるか
どのツールをどの順序で呼ぶか
どこからデータを取るか
モデル失敗時のfallback
retryロジック
タスク種別ごとの分岐
複数段階の結果の統合
logging、tracing、usage tracking
場合によってはhuman-in-the-loop
この層が明確でないと、AIロジックはシステム中に散らばります。
フロントエンドに少し
API routeに少し
helperに少し
background jobに少し
prompt fileに少し
そうなると、全体フローを把握している人がいなくなります。
AI統合が制御不能になるのは、この段階です。
4. Data / Infrastructure Layer
AI対応プロダクトは、しばしば単一のDBでは足りません。
アプリケーションDBに加えて、次のようなものが必要になりがちです。
ファイル用オブジェクトストレージ
vector store / retrieval index
job queue
cache
logging / observability
usage analytics
secret / config management
ユースケースによっては、
PostgreSQL / MySQL
Redis
S3互換ストレージ
queue worker
search / vector layer
などが入ります。
これはプロダクト開発として特別珍しいことではありません。ただ、AIによって非同期処理や非構造データ、監視対象が増えるため、より重要になります。
Full Stack JSがこの問題に向いている理由
多くのチームがAI対応製品にFull Stack JSを選ぶのには理由があります。
JavaScriptが他言語よりAI向きというより、UIからサービス層までを滑らかにつなぎやすいからです。
たとえば、
Next.js
React
TypeScript
Node.js
queue / worker
relational DB
Redis
cloud deployment
のような構成で、初期から中期のAI対応製品はかなり多く作れます。
強みは明確です。
複数レイヤーを一つの言語で通せる
開発スピードが速い
フロントとバックが近い
typesやvalidation schemaを共有しやすい
product iterationがしやすい
一方で弱みもあります。便利すぎるので、すべてを一つのアプリに押し込み続けやすいことです。その結果、オーケストレーション層がいつまでも明示化されず、AIロジックが製品ロジックに混ざっていきます。
Full Stack JSの罠は弱さではありません。
何でも一箇所に詰め込みやすい便利さです。
より健全な流れ
実務的な構成を描くなら、私は次のような流れを考えます。
ユーザーがフロントエンドで操作する。
フロントエンドはアプリケーションAPIにリクエストを送る。
APIは認証し、ユーザー文脈を読み込み、基本的なビジネスルールを確認する。
その後、処理をオーケストレーション層に渡す。
オーケストレーション層が判断する。
どのモデルを呼ぶか
retrievalが必要か
ツールや追加ワークフローが必要か
同期で返すか、background jobに回すか
その後、結果をフロントエンドに返す、あるいは状態として保存し、フロントエンドがpollingやstreamingで追えるようにする。
確かに、「モデルを呼ぶだけ」より長く見えます。ですが、ユースケースが増えても全体像を保つには、これが必要な複雑さです。
いつ同期で返し、いつjobにすべきか
これは非常に実務的な判断です。
すべてのAI機能が、1回のrequest-responseで返るべきではありません。同期で十分なものもあります。
短い文章生成
小さな入力の要約
単純分類
すばやい提案
しかし次のようなものはjobやqueueのほうが向いています。
大きな文書処理
multi-step reasoning
複数ソースからのretrieval
長いレポート生成
複数段階のpipeline
音声や動画処理
post-processingやvalidation
AI体験が悪くなる原因は、モデルの弱さではなく、長い処理を無理やり同期で返そうとする設計にあることが多いです。
UIが長く待たされる
timeoutする
retryが重なる
状態が曖昧になる
障害が見えにくくなる
オーケストレーション層とjob層が明確なら、こうした問題はかなり制御しやすくなります。
AI機能が失敗する理由は、モデルよりも信頼性にあることが多い
ここは多くのチームが後から気づきます。
AI機能のデモを作ること自体はそれほど難しくありません。モデルを呼んで、見栄えの良い出力が返れば、誰でも「すごい」と感じます。
本当に難しいのは、それを
安定させる
測定可能にする
デバッグ可能にする
コスト管理可能にする
出力が弱いときに備える
UXを壊さない
ことです。
だからAI対応製品の設計では、モデル呼び出しだけを考えてはいけません。むしろ次を考える必要があります。
timeout
retry policy
fallback response
guardrail
prompt / response metadata logging
feature単位のobservability
user feedback loop
prompt / workflow versioning
これがなければ、AI機能は「たまに動くけど、なぜ動かないのかわからない」という最悪の状態になりやすいです。
Retrieval、prompt、tool callingを散らかしてはいけない
よくある設計ミスはこうです。
promptがrouteの中に直書きされる
retrieval logicが別のhelperにある
tool callingがserviceにある
post-processingがまた別の場所にある
数スプリント後には、どこを直すと何が壊れるのかわからなくなります。
より健全なのは、AIユースケースごとに名前のついたpipelineとして扱うことです。
たとえば、
generate_product_summary
extract_invoice_fields
suggest_support_reply
build_candidate_shortlist
それぞれに対して、
入力契約
必要なcontext
retrieval step
model config
tool steps
output schema
error / fallback behavior
を持たせる。
そうするとチームは、
testしやすい
monitorしやすい
reviewしやすい
改善しやすい
モデルやpromptを差し替えやすい
状態を作れます。
AIのフロントエンドは、テキスト表示だけではない
AI対応プロダクトというと、すぐにチャットボックスを思い浮かべがちですが、実際にはもっと繊細なUIが必要です。
良いAI UIは、たとえば次を支えられるべきです。
明確なloading state
必要ならstreaming
結果比較
inline review / approve / reject
user feedback
出力品質が低いときのfallback
出力をそのまま押し付けず、編集可能にする
AIは毎回完璧な結果を出すわけではありません。だから良い製品は、AIが常に正しいふりをしません。ユーザーが、
システムが何をしているか理解できる
いつ信じてよいかわかる
いつ修正すべきかわかる
曖昧な待ち状態に陥らない
ように設計します。
ここでフロントエンドとオーケストレーション層の連携が効いてきます。
agentが必要なときと、workflowで十分なとき
ここは hype に流されやすい部分です。
もしフローがすでにかなり明確なら、
Aからデータを取る
モデルで処理する
出力を検証する
Bに保存する
UIに返す
という流れで済みます。こういう場合、多くはagentは不要です。必要なのは、きちんと設計されたworkflowです。
agentを検討すべきなのは、本当に次のような性質が必要なときです。
柔軟な複数段階の意思決定
文脈に応じたtool選択
複数行動にまたがる計画
事前に固定しにくい開放的なフロー
多くの業務用プロダクトでは、明確なworkflow、強いguardrail、健全なorchestrationのほうがずっと実用的です。
つまり、
先進的に聞こえるからという理由でagentを使わないこと。
良いAI対応アーキテクチャには何があるべきか
要約すると、私は次のような性質を持つシステムを期待します。
フロントエンドは明快だが、AIロジックを抱え込まない
API層はbusiness contractを守る
orchestration layerが明示的に分かれている
長い処理や重い処理のためのqueue / jobがある
アプリデータとworkflowデータの保存先が明確
AI機能の挙動が見えるobservabilityがある
output schema、少なくとも明確なcontractがある
fallbackとerror handlingが最初から設計されている
promptやworkflowがコードベース中に散らばっていない
最初から全部を大規模に揃える必要はありません。ただ、早い段階でこうした層を見ておくと、製品はずっと育てやすくなります。
結論
Full Stack JSでAI対応アプリケーションを作ること自体は、デモを作るだけなら難しくありません。難しいのは、AIを製品の運用可能な一部として組み込めるだけの構造を作ることです。
そのとき問いは、
「どうやってモデルを呼ぶか」
ではなくなります。
AIはアーキテクチャのどこに置くべきか
orchestration logicはどこに住むべきか
機能が増えたとき、誰が全体フローを理解できるのか
モデルが失敗したとき、システムはどう振る舞うのか
本番でどう観測し、どう改善していくのか
Full Stack JSの大きな強みは、フロントからバックまでの一貫性と開発速度です。ですが、デモを越えるには、それに加えてもう一つ必要なものがあります。
アーキテクチャの規律です。
結局、良いAI対応プロダクトとは、モデルをたくさん呼んでいるプロダクトではありません。
システムの中でAIを置くべき場所を知っているプロダクトです。